Pianificazione della Data Protection – Backup e Disaster Recovery
La data protection, sebbene costituisca uno dei pilastri della Business Continuity, è spesso considerata come un problema la cui soluzione comporta costi e complessità a fronte di garanzie limitate e difficilmente definibili. Risulta quindi fondamentale comprendere al meglio le tecnologie coinvolte, i possibili impatti sul business e le implicazioni economiche così da poter definire strategie ottimali.
Progettazione, implementazione e valutazione di un piano di protezione dei dati partono dalla definizione di metriche: alcune strettamente dipendenti dagli aspetti tecnologici ed organizzativi (RPO, RTO, SLA), altre derivanti dallo specifico contesto preso in esame (Risk Analysis, Business Impact Analysis) ed altre, infine, che rappresentano la sintesi, soprattutto da un punto di vista economico, delle precedenti (TCO e ROI).
Le diverse metriche rivestono particolare importanza per ruoli aziendali specifici, la cui estrazione e, di conseguenza, sensibilità e linguaggio sono differenti:
- Information Technology (RPO, RTO, SLA),
- Operation (SLA, RA, BIA),
- Finance (TCO e ROI).
Il problema della data protection pone quindi questioni non unicamente tecniche, ma richiede un approccio che permetta di trovare la migliore sintesi tra percezioni ed esigenze spesso contrastanti proprie delle diverse funzioni aziendali.
> Leggi anche “Business Comtinuity, Disaster Recovery e Incident Response: una strategia unificata”

Metriche Tecnologiche
Recovery Point Objective e Recovery Time Objective
L’analisi di strumenti e metodologie di data protection e backup inizia sempre con la definizione di due parametri fondamentali:
- RPO (Recovery Point Objective)
- RTO (Recovery Time Objective)
Il Recovery Point Objective rappresenta il massimo tempo che deve intercorre tra la produzione di un dato e la sua messa in sicurezza (ad esempio attraverso backup) e, conseguentemente, fornisce la misura della massima quantità di dati che il sistema può perdere a causa di guasto improvviso. Evidentemente questo valore è strettamente legato alla frequenza con cui le misure di data protection vengono poste in atto.
Il Recovery Time Objective rappresenta invece il tempo per il quale è ipotizzabile non poter disporre dei dati, ad esempio tra l’istante di danneggiamento e quello di ripristino. In sintesi, può essere definito come il tempo necessario per iniziare e condurre a termine le operazioni di recovery.
In questo ambito, la prima considerazione riguarda proprio il termine “Objective”: RTO e RPO non rappresentano valori certi, quanto situazioni estreme. Se, ad esempio, i backup dei dati vengono eseguiti di notte con cadenza giornaliera, in caso di guasto il valore medio del RPO corrisponderà alla metà dei dati prodotti nell’arco della giornata. Tuttavia, un guasto poco prima del backup determinerà una perdita pari al doppio di dati. Ridurre il valore del RPO equivale ad aumentare la frequenza delle operazioni di data protection, ricorrendo eventualmente a tecniche differenti (backup full, differenziali, incrementali, snapshot, replicazione). Evidentemente questa frequenza è determinata dalle esigenze del business e, a sua volta, stabilisce i requisiti minimi, in termini di procedure e soluzioni hardware, della protezione dei dati, ma, come vedremo, queste sono valutazioni non possibili a priori, in quanto richiedono approfondite analisi anche e soprattutto da un punto di vista economico.
Per quanto riguarda Il tempo di ripristino (RTO) è funzione di molte variabili che includono la disponibilità dell’hardware ed il tempo di riparazione (in caso di guasto fisico), la velocità di reazione, le prestazioni degli apparati. Anche in questo caso sono necessarie analisi mirate per comprendere quali siano valori accettabili e giustificabili sotto il profilo economico.
Service Level Agreement
Una volta compreso che la “O” in RPO ed RPO indica che questi parametri rappresentano un obiettivo, si presenta uno dei problemi centrali nella stesura dei piani di data protection: la definizione di un Service Level Agreement, in quanto un “obiettivo” non rappresenta una “garanzia”, sebbene sia proprio questa garanzia ciò che maggiormente interessa le business unit.
Per quanto RPO ed RTO possano essere conservativi, sono sempre riferiti a situazioni ideali che, come è facile immaginare, difficilmente si realizzano quando compaiono variabili legate a fattori umani, logistici e tecnici:
- il tempo di risposta può dipendere dall’organizzazione e dalla disponibilità del personale, quindi non è sempre determinabile a priori;
- il recovery può richiedere approvvigionamento di componenti hardware, la cui immediata disponibilità non è certa, e tempi di riparazione variabili;
- è possibile che non tutti i punti di ripristino siano consistenti ed utilizzabili, nel qual caso sarebbe necessario ricorrere a backup precedenti rispetto all’ultimo eseguito.
Malgrado questi possano considerarsi eventi sfortunati, ognuno di essi è in grado di impedire il raggiungimento degli obiettivi prefissati. Il Service Level Agreement, quindi, deve necessariamente stabilire limiti più ampi rispetto ai valori definiti da RPO ed RTO, limiti che tengano in considerazione tutti i fattori che, al di là dei processi e delle tecnologie coinvolte, allontanerebbero la realtà dallo scenario ideale: il Service Level Agreement rappresenta la promessa fornita al business di quale sia l’effettiva e reale capacità di recovery.
Nel caso più semplice è possibile definire il livello di servizio sulla base della probabilità di scostamento dai valori ideali di RPO e RTO: si tratta quindi di calcolare o stimare la probabilità e l’entità dei ritardi imputabili ai singoli eventi avversi.
Metriche Operazionali: RA e BIA
Le metriche tecnologiche ci forniscono indicazioni su quale sia il comportamento del sistema di data protection in termini di affidabilità e prestazioni, tuttavia la definizione di SLA, RPO e RTO è l’ultimo passo di un processo che deve iniziare con la definizione dell’oggetto della protezione.
Risk Analysis
La Risk Analysis (RA) permette di identificare tutte le possibili situazioni che si possono tradurre in una perdita di dati o di funzionalità.
Per giungere a questo è necessario censire tutti gli elementi facenti parte dell’infrastruttura (hardware, sistemi operativi, applicazioni, database, appliance e servizi di rete) così da poter valutare per ognuno quali siano le possibili cause di malfunzionamenti con la relativa probabilità e le conseguenze che tali malfunzionamenti determinano sugli altri componenti del sistema nel suo complesso.
I rischi da prendere in considerazione sono i più disparati e ricadono sotto diverse categorie (rischi ambientali, rischi comportamentali, rischi fisici e rischi logici):
- guasti hardware (hard disk, alimentatori, motherboard…);
- errori applicativi (crash di sistemi, errori runtime, corruzione di database, …);
- fattori umani (cancellazione o sovrascrittura dei dati, dolosa o colposa, da parte degli utenti);
- virus e malaware;
- fattori ambientali (guasti agli impianti, incendi, allagamenti, …);
- eventi naturali (inondazioni, terremoti, …).
Ad ognuno di questi eventi può essere associata una probabilità e da ognuno di essi può dipendere un effetto a catena che interessa altri ambiti con conseguenze che devono essere valutate di caso in caso.
Business Impact Analysis
L’identificazione dei rischi costituisce solo il primo passo per poter giungere alla stesura di un piano di data protection e business continuity.
Come è facilmente intuibile, i valori delle metriche tecnologiche sono sempre migliorabili aumentando gli investimenti così da garantire maggiore ridondanza, distribuzione dei dati e dei servizi, maggiori prestazioni, migliori strumenti di backup e migliore copertura da parte del personale preposto, tuttavia questa non può essere la soluzione: è necessario determinare un equilibrio tra gli investimenti ed il risultato che ne deriva in termini di mitigazione del rischio e riduzione del danno conseguente.
Per comprendere meglio le idee alla base di questi ragionamenti possiamo ricorrere ad un semplice parallelismo. Concetti come data protection e data availability sono assimilabili ad un’assicurazione: in primo luogo si stabilisce per quale evento sia necessario assicurarsi, quale sia la sua probabilità, quale sia l’impatto nel caso in cui si verifichi e quindi si acquista una protezione (una polizza) ad un prezzo prestabilito, sensibilmente più contenuto, in termini statistici, rispetto ai costi che deriverebbero dal verificarsi dall’evento in oggetto.
Analogamente, una volta identificati i rischi e le relative probabilità, la BIA ha lo scopo di tradurli non in specifiche tecniche, ma in un’analisi finanziaria che permetta di quantificare, per ogni fattore rischio, un possibile danno economico, diretto o indiretto, normalizzato con la probabilità con cui si può verificare l’evento.
La determinazione dell’impatto economico può seguire alcune linee guida generiche, ragionando ad esempio sulla base delle ore di fermo, del costo orario del personale, sia quello impossibilitato a lavorare sia quello destinato alle attività di ripristino, e dei mancati profitti. Tuttavia, se la risk analysis è facilmente declinabile per ogni realtà valorizzando nel modo corretto le probabilità connesse ai rischi, una BIA accurata non può prescindere dallo specifico contesto, prendendo in considerazione anche effetti meno diretti, quali la perdita a livello di immagine o le possibili penali in cui un’azienda può incorrere.
Risk Analysis e Business Impact Analysis non possono prescindere dalla definizione di ambiti temporali in quanto la probabilità con cui si verificano determinati eventi è funzione del periodo di osservazione per il quale vengono progettate le misure di protezione.
Metriche Finanziarie: TCO e ROI
Una volta valorizzate e calcolate le metriche funzionali siamo in grado di definire quale sia, in termini statistici, il costo atteso di una situazione di crisi (l’impatto per la probabilità). Sappiamo anche che possiamo operare dal punto di vista organizzativo e tecnico per migliorare le metriche tecnologiche (RTO e RPO) per ridurre l’impatto. Manca tuttavia ancora un passaggio: tutte le soluzioni adottate comportano costi che devono essere relazionati e confrontati con i benefici attesi, così da calibrare correttamente gli investimenti.
Total Cost of Ownership
L’implementazione di qualsiasi soluzione finalizzata a data protection, backup, business continuity determina costi di varia natura:
- licenze e sottoscrizioni (acquisti e rinnovi)
- hardware (fisico, virtuale o in cloud)
- lavoro di installazione
- lavoro di manutenzione e controllo
- contratti di manutenzione e garanzia
- supporti di archiviazione (fisici, come dischi o nastri, o virtuali in cloud)
- consumi (energia, banda, …).
La crescita dei dati o della loro variabilità nel tempo porterà anche la necessità di rivedere alcune di queste voci, aggiungendo un’ulteriore variabile da considerare nella valutazione del TCO.
A questi costi, che possiamo considerare certi, si aggiungeranno quelli connessi alle operazioni di ripristino qualora si rendessero necessarie. Se l’analisi dei rischi è stata condotta in modo accurato e realistico, è ragionevole ipotizzare che effettivamente si incorrerà nella possibilità di dover gestire queste situazioni.
Il valore del TCO è riferito all’intera durata del progetto, anche se alcuni costi si concentrano nella fase di avvio o in momenti specifici, mentre altri risultano distribuiti uniformemente per tutto il suo ciclo di vita.
Return on Investment
Con il calcolo del ROI si giunge all’ultimo passo del percorso per la definizione di un piano di data protection: questo valore, strettamente legato al rapporto tra BIA e TCO, costituisce la chiave di volta per comprendere fin dove sia ragionevole o conveniente spingersi per migliorare le metriche tecnologiche.
Introdotto il concetto di TCO è chiaro come questo sia in stretta relazione con i risultati che si possono ottenere in termini di RPO ed RTO (e quindi di SLA): idealmente possiamo infatti immaginare che tanto maggiore sarà l’investimento, tanto più efficienti saranno gli strumenti e tanto più protetti saranno i dati e, di conseguenza, il business.
Torniamo però al parallelismo con l’assicurazione: il costo di una polizza deve risultare inferiore rispetto al possibile danno che essa copre. In caso contrario sarebbe economicamente più conveniente attendere l’evento avverso ed affrontarlo qualora si verifichi. Analogamente il TCO (la nostra polizza) deve trarre la propria giustificazione dalla BIA (il danno derivato dall’evento per cui ci assicuriamo).
In modo intuitivo possiamo intendere il ROI come il rapporto tra BIA e TCO oppure come la differenza tra i due, tuttavia la formula comunemente utilizzata per rappresentarlo in termini percentuali è
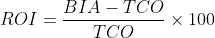
Ogni valore positivo del ROI ottenuto da questa formula può, in linea di massima, essere considerato una buona opzione; valori negativi portano invece a situazioni in cui la protezione dal rischio è più costosa dell’impatto.
Ovviamente valori eccessivamente bassi di questo rapporto, prossimi al 10%, possono non giustificare l’investimento: innanzi tutto minimi scostamenti dalle condizioni di progetto possono erodere questo margine, inoltre, molto probabilmente, in ogni azienda è immaginabile che esistano ambiti di investimento che presentano una redditività maggiore e verso i quali sarebbe più proficuo destinare i fondi.
Potrebbe sembrare un controsenso, ma anche valori eccessivamente elevati del ROI non rappresentano una buona soluzione. Un ROI del 2000%, per quanto possa sembrare allettante, nasconde in realtà molteplici insidie: potrebbe derivare da RA e BIA non condotte con sufficiente scrupolosità, da scarsa affidabilità delle soluzioni ipotizzate, oppure potrebbe essere l’indicatore di anomalie strutturali o organizzative la cui soluzione andrebbe ricercata altrove.
In un contesto di data protection è difficile stabilire quali siano valori accettabili per il ROI. In alcuni casi sono considerate buone soluzioni quelle che si attestano in un intorno del 40%, ma i fattori che concorrono sono molteplici, alcuni anche di natura umana come la propensione al rischio di chi ricopre ruoli decisionali (e la discrepanza tra il valore percepito rispetto al valore reale).
Conclusioni
Il percorso per la definizione di un piano di data protection è così concluso.
Partendo da un’attenta analisi dei rischi (Risk Analysis) e dall’impatto che ha sul business il verificarsi di determinati eventi (Business Impact Analysis) è possibile determinare quali contromisure adottare per ridurre tali effetti, imponendo limitazioni a parametri tecnologici quali RPO e RTO così da garantire adeguati livelli di servizio (SLA). Queste contromisure determinano costi (Total Cost of Ownership) che, messi in relazione con il risparmio stimato per i danni mitigati o rimossi, permettono di stabilire il ROI. Il ROI, a sua volta, costituisce l’elemento di retroazione per comprendere se le contromisure siano adeguate e giustificabili da un punto di vista finanziario.
Intenzionalmente non si è mai fatto riferimento a metodologie, soluzioni tecniche o prodotti per l’implementazione di funzioni di data protection. La protezione dei dati, la business continuity, il disaster recovery non sono prodotti o servizi: si tratta di processi la cui implementazione deriva da analisi che perlopiù esulano dagli aspetti tecnologici. La scelta degli strumenti più idonei costituisce sicuramente un elemento importante, ma deve essere sostenuta da solide basi e costituirne una conseguenza naturale.


